
Stop Fraud Before It Hits Your Bottom Line
Detelix provides continuous, automated fraud prevention across your ERP and financial processes. Talk to our experts today.
- What Is Data Analytics for Fraud Detection?
- How Does Fraud Analytics Differ from Fraud Detection?
- Why Analytics Is the Foundation for Prevention
- The Gap Between Monitoring and Control
- Architecture of a Data-Driven Fraud Detection System
- What Data Sources Power Effective Fraud Analytics?
- Common Signals That Flag Suspicious Activity
- When to Use Anomaly Detection vs. Classification
- How Network Analytics Exposes Organized Fraud
- Five Common Mistakes in Implementing Analytics Fraud Prevention
- Reducing False Positives Without Missing Real Fraud
- Measuring Success: KPIs That Matter
- How Detelix Supports Data-Driven Fraud Prevention
- Model Drift: Why Systems Degrade Over Time
- Governance, Privacy, and Explainability
- Real-Time Detection Without Disrupting the User Experience
- How Feature Engineering Determines Detection Quality
- Frequently Asked Questions
Data analytics for fraud detection has become an essential discipline for organizations that handle sensitive financial processes. Every day, thousands of transactions flow through ERP systems, payment platforms, and banking channels. Within that volume, fraudulent activity can hide in plain sight—disguised as routine operations, small-value adjustments, or legitimate-looking vendor payments. Traditional controls such as manual approvals, periodic audits, and static rule sets were designed for a slower, simpler era. They often catch problems only after the damage has been done. The shift toward data-driven fraud detection reflects a broader recognition: organizations need continuous, automated visibility into what is actually happening across their financial operations—not just a retrospective review of what already went wrong.
Key Takeaways
- Data analytics transforms fraud detection from a reactive audit exercise into a continuous, real-time control mechanism that catches anomalies before losses materialize.
- Effective fraud prevention combines rules-based logic for clear-cut scenarios with machine learning models that adapt to evolving attack patterns.
- Feature engineering—not algorithm selection—is the single most impactful factor in determining detection quality and reducing false positives.
- Model drift is inevitable: fraud detection systems must be continuously monitored and retrained as attacker tactics evolve.
- Network (graph) analytics reveals organized fraud schemes that appear completely legitimate when individual transactions are analyzed in isolation.
- Detelix provides an independent, automated control layer over ERP-driven processes, delivering real-time alerts on vendor changes, payment anomalies, and segregation of duties violations.
What Is Data Analytics for Fraud Detection?
Data analytics for fraud detection is the systematic use of statistical methods, machine learning models, and computational techniques to identify suspicious patterns within transactional and behavioral data. Rather than relying on a single auditor reviewing spreadsheets, this approach processes large volumes of information continuously—flagging anomalies, scoring risk levels, and surfacing events that deviate from established norms.
The scope extends well beyond payment card fraud: it covers supplier payment manipulation, payroll irregularities, procurement kickbacks, unauthorized bank account changes, and more. At its core, data analytics for fraud detection transforms raw operational data into actionable intelligence, enabling finance and risk teams to intervene before losses materialize.
Tip
Start your fraud analytics journey by cataloguing every data source that touches your financial processes—ERP logs, payment gateways, HR systems, and vendor portals. The broader your data foundation, the more effective your detection models will be from day one.
How Does Fraud Analytics Differ from Fraud Detection?
These two terms are often used interchangeably, but they serve distinct purposes. Fraud detection refers to the operational, real-time decision: should this specific transaction be approved, flagged, or blocked? It is the “yes or no” mechanism embedded in payment flows and approval chains.
Fraud analytics, on the other hand, is the broader discipline that feeds and refines the detection engine. It encompasses trend analysis, historical pattern mining, model training, investigator workflows, and strategic reporting. Think of fraud detection as the alarm system, and fraud analytics as the intelligence unit that decides where to place the sensors, how sensitive they should be, and how to interpret the signals they produce. Over time, strong analytics makes detection sharper, more accurate, and more adaptive to new threats.
Did You Know
Organizations that invest in dedicated fraud analytics capabilities—separate from their operational detection systems—typically reduce false positive rates by 40-60% within the first year, because the analytics layer continuously refines the detection models based on investigator feedback and confirmed case outcomes.
Why Analytics Is the Foundation for Prevention—Not Just After-the-Fact Discovery
Many organizations still treat fraud as a problem you discover during an annual audit or a reconciliation exercise. Analytics changes that equation fundamentally. By analyzing historical attack patterns, failed attempts, and behavioral baselines, analytics fraud prevention identifies vulnerabilities before they are fully exploited.
Consider a scenario where a fraudster “tests” a compromised vendor account with a small payment before escalating to a large one. A well-tuned analytics system recognizes the test payment as an anomaly—flagging it in real time, not months later. This proactive stance shortens the window of opportunity for bad actors and strengthens the overall control environment. Organizations that use ML-based fraud and anomaly detection across business areas like pricing and collections can catch revenue leakage and manipulation before they mature into significant losses.
Tip
Establish behavioral baselines for every vendor, employee, and transaction type in your system. Without a clear definition of “normal,” even the best detection model cannot reliably identify what is abnormal.
A Scenario That Illustrates the Gap Between Monitoring and Control
Imagine a mid-size manufacturing company with a well-documented approval process for supplier payments. Every invoice is signed off by a manager, and the ERP system logs each transaction. On paper, controls are solid.
In practice, an employee in the accounts payable department has been slowly redirecting payments to a shell company by making small, incremental changes to vendor bank details. Each change looked routine. No single transaction was large enough to trigger a manual review. It took eighteen months and over $400,000 in losses before the scheme was uncovered during an external audit.
A data-driven fraud detection system would have flagged the pattern far earlier: repeated bank detail changes for the same vendor, payments to a newly created account, and amounts that deviated from the historical norm. The difference between monitoring (logging events) and controlling (acting on anomalies in real time) is the difference between discovering fraud and preventing it. Understanding the dangers of changing bank account details in ERP systems is a critical first step for any organization serious about closing this gap.

Did You Know
According to the Association of Certified Fraud Examiners, the median duration of an occupational fraud scheme is 12 months before detection. Schemes involving billing or vendor manipulation tend to run even longer because they mimic legitimate business processes.
Typical Architecture of a Data-Driven Fraud Detection System
Building effective fraud analytics requires more than a single algorithm. It demands an architecture that supports speed, accuracy, and continuous improvement. Most mature systems follow a layered approach that separates data ingestion, feature computation, decisioning, and investigation.
Data Ingestion and Processing Speed
The first layer collects data from multiple sources: ERP master data, payment gateways, user session logs, device fingerprints, and external reference databases. The ingestion pipeline must handle high volumes with minimal latency, because delays in data availability translate directly into delays in detection. Batch processing may suffice for retrospective analysis, but real-time fraud prevention demands streaming architectures that process events within milliseconds.
Feature Engineering and Real-Time Computation
Raw data alone is not enough. It must be transformed into “features”—calculated variables that capture meaningful context. Examples include the number of login attempts in the past ten minutes, the deviation of a transaction amount from the account holder’s 90-day average, or the geographic distance between two consecutive transactions. A feature store enables pre-computation and caching so that scoring engines can access these variables instantly, without recalculating from scratch for every event.
The Decisioning Engine
This is where rules and models converge. Static rules handle clear-cut scenarios—for example, blocking any payment to a sanctioned entity. Machine learning models handle nuance, producing a risk score that reflects the probability of fraud based on dozens or hundreds of features. The decisioning engine combines both inputs to generate an action: approve, step-up verify, queue for review, or block outright. The most effective systems allow graduated responses rather than binary decisions, reducing unnecessary friction for legitimate users.
Tip
When designing your decisioning engine, map out at least four response tiers—auto-approve, soft alert, step-up verification, and hard block. Binary pass/fail systems create excessive friction and miss opportunities for graduated risk management.
What Data Sources Power Effective Fraud Analytics?
The quality of fraud analytics depends directly on the breadth and depth of available data. Key categories include transactional data (amounts, currencies, timestamps, counterparties), identity and account data (changes to addresses, phone numbers, bank details), technical signals (IP addresses, device fingerprints, browser metadata), and behavioral patterns (navigation sequences, typing speed, session duration).
Historical baselines are equally important—understanding what “normal” looks like for a specific account, vendor, or business unit is essential for identifying what deviates. Standardized messaging formats such as ISO 20022 improve the richness and structure of financial transaction data, making automated analytics more reliable and reducing ambiguity in cross-border or multi-system environments.
Common Signals That Analytics Uses to Flag Suspicious Activity
| Signal Category | Examples | Why It Matters |
|---|---|---|
| Velocity | Multiple transactions or login attempts in a short window | Indicates automated attacks or account takeover attempts |
| Identity Inconsistency | New device + new location + recent contact detail change | Suggests compromised credentials or synthetic identity |
| Amount Deviation | Transaction significantly above or below historical average | May indicate manipulation or unauthorized access |
| Entity Linkage | Multiple accounts sharing the same device, email, or address | Points to fraud rings or collusion |
| Temporal Anomaly | Transactions at unusual hours or on holidays | Deviates from established behavioral baseline |
| Master Data Changes | Bank account or supplier detail modifications before large payments | Classic internal fraud pattern in ERP environments |
Did You Know
Master data manipulation—specifically changes to vendor bank account details shortly before large payments—is one of the most common and costly internal fraud patterns in ERP environments. It often bypasses standard approval workflows because each individual change appears routine.
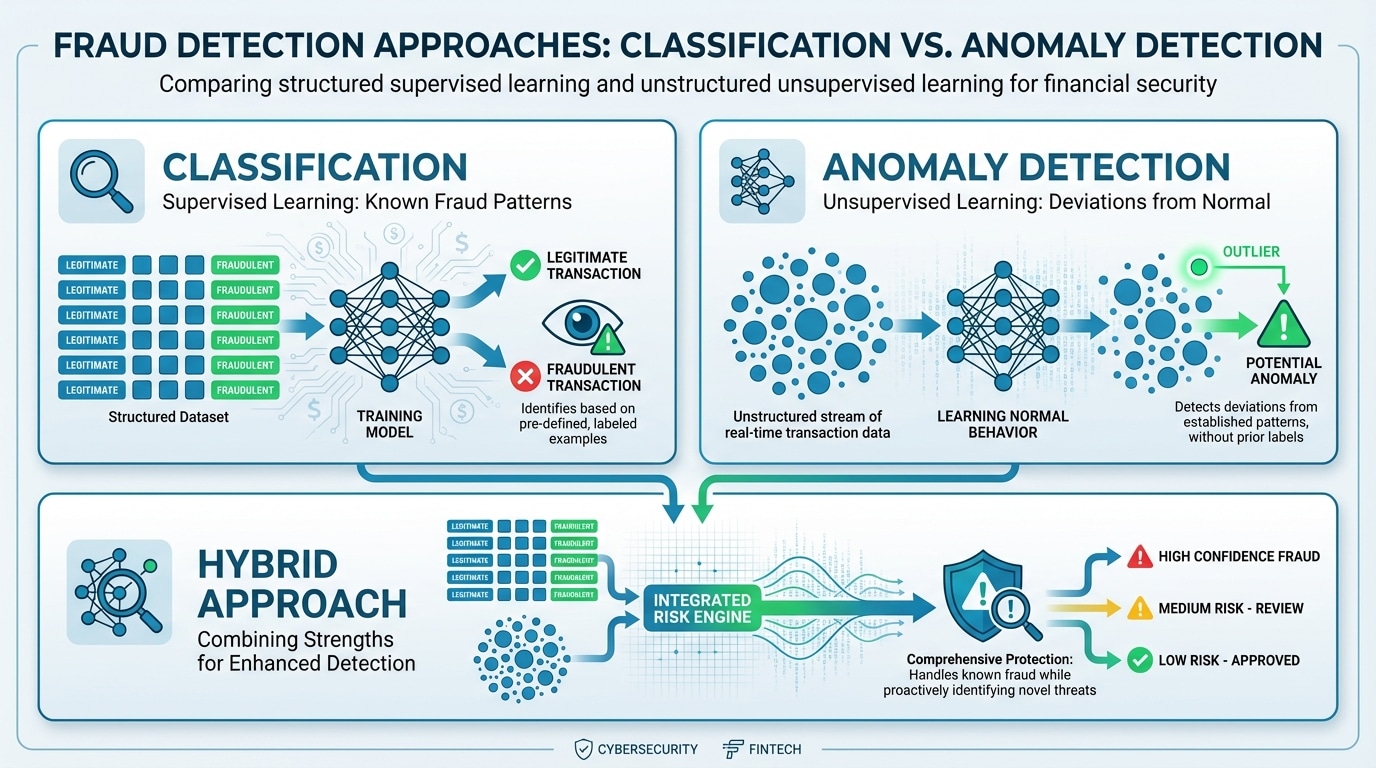
When Should You Use Anomaly Detection Instead of Classification?
Classification models (supervised learning) work well when you have a substantial, well-labeled dataset of past fraud cases. The model learns the characteristics of known fraud and applies those patterns to new events. But fraud is rare and constantly evolving—labeled datasets are often incomplete or outdated.
Anomaly detection (unsupervised learning) fills this gap by identifying events that deviate from “normal” behavior without requiring fraud labels. It excels at catching novel attack patterns that have never been seen before. The trade-off is clear: anomaly detection casts a wider net but generates more false positives, while classification is more precise but may miss entirely new fraud types. Most mature organizations use both approaches in tandem—classification for known patterns and anomaly detection as a safety net for emerging threats.
How Network Analytics Exposes Organized Fraud
Individual transactions can look perfectly legitimate in isolation. Network (graph) analytics reveals what single-event analysis cannot: the hidden connections between entities. By mapping relationships between accounts, devices, IP addresses, phone numbers, and payment destinations, graph-based methods uncover fraud rings, money mule networks, and collusive schemes.
For example, if ten seemingly unrelated vendor accounts all share the same bank account or the same device fingerprint, a graph model surfaces this cluster as high-risk—even though each individual vendor transaction appears normal. Recent research on Graph Neural Networks for real-time fraud detection demonstrates that these techniques can operate at the speed required for online decisioning, handling the latency challenges inherent in production environments.
Your ERP data holds the signals that reveal fraud—but only if you have the right tools to listen. Detelix turns raw transactional data into real-time, actionable fraud prevention.
Five Common Mistakes in Implementing Analytics Fraud Prevention
Organizations investing in data-driven fraud detection often stumble on operational, rather than technical, challenges. Recognizing these pitfalls early saves significant time and cost.
Overreliance on a model without operational workflow. A model that produces scores but lacks clear escalation paths, investigator queues, and feedback loops delivers limited value. Detection without response is incomplete.
Neglecting data quality. Garbage in, garbage out. If vendor master data is inconsistent, transaction timestamps are unreliable, or historical labels are inaccurate, even the best algorithm will underperform.
Measuring only model accuracy, not business impact. A 99% accuracy rate sounds impressive—until you realize that in a dataset where only 0.1% of events are fraudulent, a model that labels everything as “legitimate” already achieves 99.9% accuracy. Business-relevant metrics (losses prevented, investigation efficiency, customer friction) matter far more.
Ignoring model drift. Fraudsters adapt. A model trained on last year’s attack patterns may be ineffective against this quarter’s tactics. Without continuous monitoring, performance degrades silently.
Flooding investigators with alerts. Too many false positives erode trust in the system. Analysts begin to dismiss alerts reflexively, and real fraud slips through unnoticed. Calibration and graduated responses are essential.
Tip
Create a formal feedback loop between your fraud investigators and your analytics team. Every confirmed case and every dismissed false positive is training data that makes the next generation of models more accurate.
Reducing False Positives Without Missing Real Fraud
False positives represent one of the most significant operational costs in fraud prevention. Every false alarm consumes investigator time, creates customer friction, and gradually undermines confidence in the detection system. Reducing them requires a multi-layered approach rather than a single technical fix.
Segmentation by Risk Profile
Not all accounts, vendors, or transaction types carry the same risk. Applying a single threshold across the entire portfolio inevitably over-flags low-risk segments and under-flags high-risk ones. Segmenting models and rules by customer type, geography, channel, and business unit allows for calibrated sensitivity. A new vendor in a high-risk category warrants tighter scrutiny than a long-standing supplier with consistent payment history.
Step-Up Verification Instead of Outright Blocking
Modern systems use graduated responses. Instead of blocking a transaction that scores above a certain threshold, the system can trigger additional verification—a one-time passcode, a callback to the account holder, or a manager approval step. This approach, supported by ECB/EBA findings on strong authentication, reduces friction for legitimate users while still intercepting suspicious activity. The key insight from regulatory data is that while strong authentication significantly lowers fraud rates, criminals continuously adapt—meaning verification methods themselves must evolve.
Did You Know
Step-up verification—where only medium-risk transactions receive additional authentication challenges—can reduce false positive rates by up to 50% compared to binary block/allow systems, while maintaining the same or higher fraud catch rates.
Measuring Success: KPIs That Matter for Fraud Analytics
| KPI | What It Measures | Why It Matters |
|---|---|---|
| Detection Rate (Recall) | Percentage of actual fraud that the system catches | Directly reflects protection effectiveness |
| False Positive Rate | Percentage of flagged events that are legitimate | Impacts investigator workload and customer experience |
| Precision | Percentage of flagged events that are actually fraud | Measures signal quality for investigation teams |
| Time-to-Detect | Elapsed time from fraudulent action to alert | Shorter times reduce loss magnitude |
| Investigator Productivity | Ratio of alerts reviewed to confirmed cases | Indicates operational efficiency of the alert pipeline |
| Loss Prevention Rate | Dollar value of fraud prevented vs. total fraud attempted | The ultimate business outcome metric |

Tracking these KPIs consistently requires clean, well-structured data. The ECB Data Portal’s documentation on fraud data quality underscores that even established institutions face challenges in ensuring the accuracy and comparability of fraud metrics—making internal data governance a prerequisite for reliable measurement.
Tip
Track your Loss Prevention Rate alongside your False Positive Rate on a weekly basis. If losses prevented are rising while false positives are stable or declining, your system is improving. If both are rising, your models may need recalibration rather than just more sensitivity.
How Detelix Supports Data-Driven Fraud Prevention Across ERP Processes
| Business Need | How Detelix Helps |
|---|---|
| Continuous monitoring of sensitive master data changes | Automatically cross-checks vendor bank detail modifications, flagging unauthorized or unusual changes before payments are released |
| Real-time alerts on payment anomalies | Scores supplier payments against historical baselines and behavioral profiles, sending actionable alerts to finance teams |
| Segregation of duties enforcement | Identifies policy violations where the same individual creates a vendor, approves an invoice, and authorizes payment |
| Reduction of manual review burden | Prioritizes high-risk events so investigators focus on cases that matter, improving productivity and reducing alert fatigue |
| Audit-ready documentation | Maintains a complete log of every alert, review, and decision, supporting regulatory compliance and internal audit requirements |
Detelix functions as an organizational gatekeeper, providing an independent control layer over ERP-driven processes. Rather than replacing existing approval flows, it augments them with continuous, automated cross-checks—giving finance leaders visibility into what is actually happening, not just what the approval chain says should happen.
Did You Know
Segregation of duties violations—where one person controls multiple steps in a financial process—are present in over 30% of occupational fraud cases. Automated enforcement through systems like Detelix eliminates these blind spots without adding manual overhead.
Model Drift: Why Fraud Detection Systems Degrade Over Time
Fraud is not static. Attackers study detection patterns, share tactics, and pivot to new methods when old ones stop working. This dynamic creates “concept drift”—a gradual shift in the statistical relationship between features and fraud outcomes that causes model performance to decline.
A model trained on last year’s business email compromise patterns may be blind to this year’s deepfake voice authorization attacks. Research on robust online streaming fraud detection demonstrates that intelligent systems should monitor their own performance metrics and trigger retraining only when drift is detected, rather than on a fixed calendar schedule. This approach balances computational efficiency with detection accuracy.
Early Warning Signs of Drift
Key indicators include a rising false positive rate with no corresponding increase in confirmed fraud, a decline in precision or recall on recent data, and distributional shifts in key features (for example, a sudden increase in transaction amounts or a change in the geographic mix of events). Statistical drift detection methods provide formal frameworks for identifying these shifts before they lead to significant blind spots.
Retraining Strategies
Best practice involves maintaining a “champion/challenger” framework: the current production model (champion) runs alongside a retrained candidate (challenger). Performance is compared on live data before any model is promoted. This prevents the risk of deploying a worse model and ensures that retraining produces measurable improvement. Detelix supports this philosophy by continuously validating its detection logic against actual outcomes, ensuring that its alerts remain relevant as operational patterns evolve.
Tip
Set up automated drift monitoring dashboards that track your model’s precision and recall on a rolling 30-day window. When either metric drops below a predefined threshold, trigger a champion/challenger evaluation cycle rather than waiting for quarterly reviews.
Governance, Privacy, and Explainability in Fraud Analytics
Deploying sophisticated analytics raises important questions about transparency, accountability, and data protection. Investigators need to understand why a particular transaction was flagged—not just that it received a high score.
The NIST AI Risk Management Framework emphasizes that AI systems used for risk decisions must be explainable, transparent, and secure throughout their lifecycle. In practice, this means providing “top driver” explanations with every alert (for example: “This payment was flagged because the vendor bank account was changed 48 hours ago, the amount is 3x the historical average, and the approver is the same person who created the vendor record”). Clear explanations accelerate investigation, improve decision consistency, and build organizational trust in the system.

Privacy compliance adds another layer. Fraud analytics requires access to sensitive personal and financial data, which must be handled within the boundaries of applicable regulations. Encryption, access controls, data minimization, and clear retention policies are non-negotiable. Using aggregated or anonymized data where possible—and ensuring strict segregation of duties between analysts, investigators, and system administrators—protects both the organization and its stakeholders.
Did You Know
The NIST AI Risk Management Framework specifically calls out fraud detection as a domain where explainability is critical—not just for regulatory compliance, but because investigators who understand the reasoning behind an alert resolve cases 3-4x faster than those working with opaque risk scores.
How Real-Time Detection Works Without Disrupting the User Experience
One of the most common concerns about real-time fraud detection is that it will slow down business operations or frustrate legitimate users. In practice, well-designed systems avoid this by pre-computing features, caching risk scores, and using asynchronous processing wherever possible.
The vast majority of transactions—typically over 95%—are approved instantly with no additional friction. Only the small percentage that triggers a risk threshold receives a graduated response: additional verification for moderate risk, and hold-for-review for high risk. This tiered approach protects the organization without creating bottlenecks. The key is precision: better features, better segmentation, and better models reduce the number of legitimate events that require intervention, keeping the operational flow smooth while maintaining strong controls.
How Feature Engineering Determines Detection Quality
The most impactful differentiator in fraud analytics is not the choice of algorithm—it is the quality of features. Strong features capture context, change, and pace. They answer questions like: “How different is this event from what is typical for this entity?” and “How quickly are changes occurring?”
Examples include time elapsed since the last password reset, the ratio of current transaction amount to the 30-day rolling average, the number of distinct bank accounts associated with a vendor in the past quarter, and the geographic distance between the approver’s last login location and the current session. Features that combine multiple data dimensions—linking behavioral, transactional, and identity signals—consistently outperform those derived from any single source. Investing in feature engineering is one of the highest-return activities for any fraud prevention program.
Tip
Prioritize ratio-based and velocity-based features over absolute values. A $10,000 payment means very different things depending on whether the vendor’s average payment is $9,500 or $500. Context-aware features dramatically outperform raw amount thresholds.
Are your current controls providing real visibility into what is happening across your financial processes right now—or are you relying on periodic reviews that reveal problems only after the fact? If you are ready to move from routine monitoring to real control, reach out to the Detelix team and discover how continuous, automated cross-checks can protect your organization before losses materialize.
Detelix Fraud Prevention Solutions
Proactive Monitoring
Continuous surveillance of ERP master data and financial transactions to detect anomalies before they become losses.
Real-Time Alerts
Instant notifications on suspicious vendor changes, payment deviations, and segregation of duties violations.
Gatekeeper
An independent control layer that cross-checks every critical financial action against policy rules and behavioral baselines.
Experience-Driven Detection
ML models trained on real-world fraud patterns across industries, continuously refined by investigator feedback loops.
See Detelix in Action
Frequently Asked Questions
Can data analytics truly prevent fraud, or does it only detect it after the fact?
Analytics can do both, but its greatest value lies in prevention. By identifying early signals—such as unusual master data changes, velocity anomalies, or behavioral deviations—a well-configured system intervenes before money leaves the organization. The shift from after-the-fact discovery to real-time prevention is the defining advantage of modern data-driven fraud detection.
What is the difference between rules-based and machine learning-based fraud detection?
Rules-based systems apply fixed logic (“block any payment over $50,000 to a new vendor”). They are transparent and easy to audit but rigid—they cannot adapt to new attack patterns without manual updates. Machine learning models learn from data and adapt over time, identifying complex patterns that rules would miss. The most effective systems combine both: rules for regulatory requirements and clear-cut scenarios, models for nuance and evolving threats.
How often should fraud detection models be retrained?
There is no universal cadence. The right frequency depends on how quickly fraud patterns shift in your environment. Rather than retraining on a fixed schedule, best practice is to monitor model performance continuously and retrain when performance metrics indicate drift. Some organizations retrain monthly; others update only when specific thresholds are crossed. Champion/challenger testing before deployment prevents regressions.
Is it possible to perform fraud analytics while complying with data privacy regulations?
Yes. Privacy and fraud prevention are not mutually exclusive. Key practices include data minimization (collect only what is necessary), encryption at rest and in transit, strict access controls, clear retention policies, and anonymization or aggregation where feasible. Well-designed governance frameworks ensure that analytics teams can access the data they need for detection without violating privacy obligations.
What role does explainability play in fraud detection systems?
Explainability is critical for operational effectiveness. Investigators need to understand why a transaction was flagged to make informed decisions quickly. Systems that provide “top driver” explanations—identifying the specific features that contributed most to a risk score—reduce investigation time, improve decision quality, and support audit requirements. Without explainability, fraud teams may lose trust in automated alerts, undermining the entire program.
How does Detelix differ from a generic monitoring dashboard?
Detelix is not a passive reporting tool. It functions as an active control layer over ERP-driven financial processes, continuously cross-checking sensitive actions—such as vendor creation, bank detail changes, payment approvals, and segregation of duties—against behavioral baselines and policy rules. It generates real-time, actionable alerts rather than historical reports, enabling finance teams to intervene before damage occurs rather than discovering it weeks or months later.
Ready to Move from Reactive Audits to Real-Time Fraud Prevention?
Discover how Detelix gives your finance team continuous visibility and automated control over every critical ERP process. Schedule a personalized assessment today.


